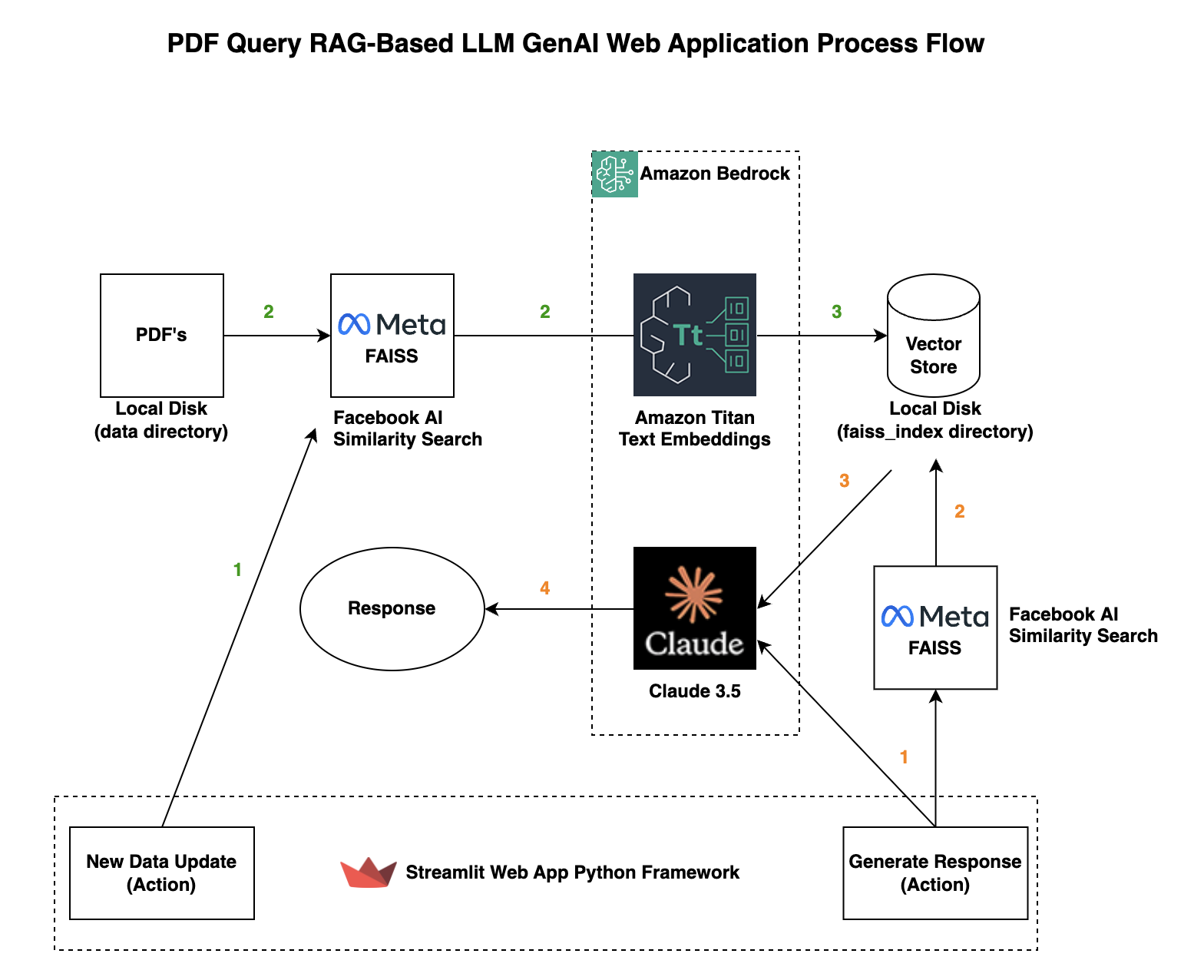
This article will cover building a Generative AI PDF query web application that uses a retrieval-augmented generation (RAG) architecture. The PDF query web application will go through your PDF’s and provide you responses to your questions based on what is in your PDF’s. The importance of using RAG is the ability to scope the results of the generated response from the LLM in our case Claude 3.5 Sonnet with up-to-date, accurate, reliable responses. RAG allows for domain-specific contextually relevant responses tailored to your data rather than static training data.
The PDF query web application will leverage Facebook AI Similarity Search (FAISS) and Amazon Titan Embeddings to create vector representations of unstructured text and the storage/search of those embeddings. LangChain is utilized for the prompt template guiding the models response, RetrievalQA for pertinent data, and various PDF processing tools. We will use Amazon Bedrock to access Claude 3.5 Sonnet and Amazon Titan Embeddings.
Code:
GitHub repo with files referenced in this blog pdf-query-rag-llm-app
Prerequisites:
- Amazon Web Services Account
- Enable Amazon Bedrock Access (Specifically Amazon Titan Embeddings and Claude 3.5 Sonnet) see: Manage access to Amazon Bedrock foundation models
- EC2 Instance Role with AmazonBedrockFullAccess Policy Attached (note you can make this more secure by making a custom policy)
- Verified on EC2 Instance Ubuntu 22.04 and Ubuntu 24.04
- Verified with Python 3.10, 3.11, 3.12
- Virtualenv
- AWS Default Region is set to us-east-1 you can change the region in the
pdf_query_rag_llm_app.pyfile underregion_name='us-east-1'
AWS Resource Cost:
As with most AWS services you will incur costs for usage.
EC2 Ubuntu Instance Setup:
(This article assumes you have a ubuntu user with /home/ubuntu)
Step 0
Install some dependencies.
sudo apt -y update
sudo apt -y install build-essential openssl
sudo apt -y install libpq-dev libssl-dev libffi-dev zlib1g-dev
sudo apt -y install python3-pip python3-dev
sudo apt -y install nginx
sudo apt -y install virtualenvwrapper
Step 1
Setup the Python environment.
cd /home/ubuntu
virtualenv pdf-query-rag-llm-app_env
source pdf-query-rag-llm-app_env/bin/activate
Step 2
Create a directory for your project.
mkdir /home/ubuntu/pdf-query-rag-llm-app
cd /home/ubuntu/pdf-query-rag-llm-app
Step 3
Create a file requirements.txt for your Python dependencies.
vim requirements.txt
awscli
pypdf
streamlit
boto3
faiss-cpu
langchain-aws
langchain_community
Install your Python dependencies.
pip install -r requirements.txt
Step 4
Create a file pdf_query_rag_llm_app.py which has the PDF query application code.
cd /home/ubuntu/pdf-query-rag-llm-app
vim pdf_query_rag_llm_app.py
import os
import boto3
import streamlit as st
from langchain_aws import BedrockEmbeddings
from langchain_aws.chat_models import ChatBedrock
from langchain_community.vectorstores.faiss import FAISS
from langchain_community.document_loaders.pdf import PyPDFDirectoryLoader
from langchain.chains.retrieval_qa.base import RetrievalQA
from langchain.prompts import PromptTemplate
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.globals import set_verbose
set_verbose(False)
bedrock = boto3.client(service_name='bedrock-runtime', region_name='us-east-1')
titan_embeddings = BedrockEmbeddings(model_id="amazon.titan-embed-text-v1", client=bedrock)
# Data Preparation
def data_ingestion():
loader = PyPDFDirectoryLoader("data")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=500)
docs = text_splitter.split_documents(documents)
return docs
# Vector Store Setup
def setup_vector_store(documents):
vector_store = FAISS.from_documents(
documents,
titan_embeddings,
)
vector_store.save_local("faiss_index")
# LLM Setup
def load_llm():
llm = ChatBedrock(model_id="anthropic.claude-3-5-sonnet-20240620-v1:0", client=bedrock, model_kwargs={"max_tokens": 2048})
return llm
# LLM Guidelines
prompt_template = """Use the following pieces of context to answer the question at the end. Follow these rules:
1. If the answer is not within the context knowledge, state that you do not know, and do not fabricate an answer.
2. If you find the answer, create a detailed, and concise response to the question. Aim for a summary of max 200 words.
3. Do not add extra information not within the context.
{context}
Question: {question}
Helpful Answer:"""
# Prompt Template
prompt = PromptTemplate(template=prompt_template, input_variables=["context", "question"])
# Create QA Chain
def get_result(llm, vector_store, query):
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vector_store.as_retriever(
search_type="similarity", search_kwargs={"k": 3}
),
chain_type_kwargs={"prompt": prompt},
return_source_documents=True,
)
# Apply LLM
result = qa_chain.invoke(query)
return result['result']
# Streamlit Frontend UI Section
def streamlit_ui():
st.set_page_config("PDF Query RAG LLM Application")
st.markdown("""
""", unsafe_allow_html=True)
st.header("PDF Query with Generative AI")
user_question = st.text_input(r":gray[$\textsf{\normalsize Ask me anything about your PDF collection.}$]")
left_column, middleleft_column, middleright_column, right_column = st.columns(4, gap="small")
if left_column.button("Generate Response", key="submit_question") or user_question:
# first check if the vector store exists
if not os.path.exists("faiss_index"):
st.error("Please create the vector store first from the sidebar.")
return
if not user_question:
st.error("Please enter a question.")
return
with st.spinner("Generating... this may take a minute..."):
faiss_index = FAISS.load_local("faiss_index", embeddings=titan_embeddings,
allow_dangerous_deserialization=True)
llm = load_llm()
st.write(get_result(llm, faiss_index, user_question))
st.success("Generated")
if middleleft_column:
st.empty()
if middleright_column:
st.empty()
if right_column.button("New Data Update", key="update_vector_store"):
with st.spinner("Updating... this may take a few minutes as we go through your PDF collection..."):
docs = data_ingestion()
setup_vector_store(docs)
st.success("Updated")
if __name__ == "__main__":
streamlit_ui()
Step 5
Create a data directory to hold your PDF’s. *note you will want to put your PDF’s in this directory that you want to query..
cd /home/ubuntu/pdf-query-rag-llm-app
mkdir data
Step 6
Create a Systemd service file. Systemd is a service manager and in this use case it will manage streamlit.
sudo vim /etc/systemd/system/pdf-query-rag-llm-app.service
Add the following to pdf-query-rag-llm-app.service
[Unit]
Description=PDF query with Generative AI Service
After=network.target
[Service]
User=root
Group=root
WorkingDirectory=/home/ubuntu/pdf-query-rag-llm-app
Environment="PATH=/home/ubuntu/pdf-query-rag-llm-app_env/bin"
ExecStart=/home/ubuntu/pdf-query-rag-llm-app_env/bin/streamlit run /home/ubuntu/pdf-query-rag-llm-app/pdf_query_rag_llm_app.py --server.port 8080 --server.headless true
[Install]
WantedBy=multi-user.target
Step 7
Start your application via Systemd and enable it to auto start after reboot
sudo systemctl start pdf-query-rag-llm-app.service
sudo systemctl enable pdf-query-rag-llm-app.service
Step 8
Create your applications NGINX config nginx_ai-image-generator.conf that makes NGINX listen on port 80 and proxies requests to Streamlit on port 8080. NGINX will help with connection handling increasing performance.
sudo vim /etc/nginx/sites-available/nginx_pdf-query-rag-llm-app.conf
Add the following to nginx_pdf-query-rag-llm-app.conf
server {
listen 80 default_server;
location / {
include proxy_params;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_buffers 8 24k;
proxy_buffer_size 4k;
proxy_pass http://127.0.0.1:8080;
}
location /_stcore/stream {
proxy_pass http://127.0.0.1:8080/_stcore/stream;
proxy_http_version 1.1;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $host;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_read_timeout 86400;
}
}
Step 9
Delete your default NGINX conf file, enable your new NGINX conf and restart NGINX (Port 80)
sudo rm /etc/nginx/sites-enabled/default
sudo ln -s /etc/nginx/sites-available/nginx_pdf-query-rag-llm-app.conf /etc/nginx/sites-enabled
sudo systemctl restart nginx
Step 10
Test your application, remember to put your PDF’s that you want to query in the data directory on the instance and click New Data Update before querying.
http://{yourhost}
Notes:
- Make sure to open up port 80 in your EC2 Security Group associated to the instance.
- For HTTPS (TLS) you can use AWS ALB or AWS CloudFront.
- Depending on how many PDF’s you have, how big the PDF’s are, and your CPU specifications using the New Data Update button can take awhile as it builds your vector embeddings.
- Any time you add PDF’s or change them make sure to click “New Data Update” to update/build your vector embeddings.
- This application does not take into consideration security controls, that is your responsibility.
- Please read Amazon Bedrock FAQ’s for general questions about AWS LLM resources used.
Summary:
Hopefully this blog article helps you create a generative AI PDF query web application which is scoped to your specific data and context leveraging a RAG architecture. Retrieval-augmented generation (RAG) is a powerful architecture choice to both leverage a trained model in this case Claude 3.5 Sonnet, and your organizations specific data (vectorized) without re-training the LLM model, but rather augmenting its knowledge base.
If you like this blog article you may want to read my other article on Building an Asynchronous GenAI Image Generator API.